Um dos objetivos da maioria dos administradores de sistemas é fazer o possível para planejar e implementar seus servidores para prover redundância e tolerância a falha. Caso ocorra uma falha em um componente de hardware, a aplicação deverá continuar disponível e, se possível, sem nenhuma interrupção.
Particularmente no ambiente POWER, a virtualização de I/O necessita de um componente adicional chamado Virtual I/O Server (VIOS) – um software appliance, baseado em AIX, cuja função é compartilhar as interfaces físicas entre as outras partições no mesmo servidor POWER, fazendo a interface entre a infraestrutura física e virtual. Neste contexto, as partições que utilizam o VIOS para acesso aos dispositivos de I/O são chamadas de partições cliente.
Considerando então que este componente é fundamental para acesso aos dispositivos de I/O e que também está sujeito à falhas, tipicamente sua implementação é feita através do provisionamento de dois servidores VIOS, evitando assim o ponto único de falha.
Porém, apenas instalarmos dois servidores VIOS não é o suficiente para conseguirmos partições com tolerância a falha. Suas configurações devem ser feitas levando em conta esta arquitetura.
Cientes disto, veremos a seguir quais são as estratégias de implementação da infraestrutura de Virtual Ethernet quando estamos trabalhando com dois servidores VIOS.
SEA Failover
Esta é a implementação mais conhecida. Aqui, a partição cliente se conecta apenas em um Virtual Switch, onde ambos os VIOS também estão conectados, utilizando o mesmo VLAN ID.
Um canal de controle é configurado entre os servidores VIOS, cujo propósito é trocar mensagens de heartbeat, de maneira semelhante a um cluster de alta disponibilidade. Portanto, se algum dos servidores VIOS ficar indisponível, o outro servidor não receberá mais as mensagens de heartbeat através do canal de controle e poderá executar as ações para correção.
O mais importante a dizer sobre esta configuração é que somente um dos servidores VIOS é responsável por enviar e receber o tráfego de rede. O outro servidor VIOS fica apenas monitorando através do canal de controle e assume a tarefa em caso de indisponibilidade do servidor primário.
O diagrama abaixo ilustra um típico exemplo de configuração do SEA Failover.
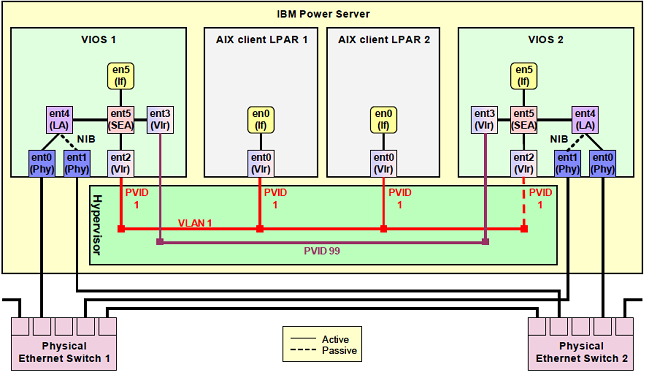
Neste diagrama, o canal de controle é estabelecido entre as interfaces ent3 dos dois servidores VIOS, configuradas na VLAN 99.
Cada servidor VIOS possui duas interfaces físicas (ent0 e ent1) que devem estar conectadas em switches físicos diferentes. Foi configurado um dispositivo Link Aggregation (LA) para tolerância a falha destas interfaces, representados pelo ent4 de cada servidor VIOS.
Finalmente, são configuradas as pontes entre as interfaces físicas e virtuais, conhecido como SEA (Shared Ethernet Adapter). Estas interfaces, representadas pela ent5, faz a junção entre a interface de Link Aggregation ent4 e a interface virtual ent2, conectada na VLAN 1.
Na partição cliente, basta agora adicionar uma interface virtual conectada ao mesmo Virtual Switch, representada pela ent0 das partições. Nesta configuração, é possível inclusive definir um VLAN ID diferente para cada partição cliente.
Não entendeu nada? Vamos discutir alguns cenários para esclarecer o funcionamento desta configuração.
Levaremos em consideração que o VIOS 1 é o servidor primário, portanto, o tráfego de rede das duas partições cliente são enviadas para ele.
Em caso de falha na interface física ent0 do VIOS 1? O Link Aggregation irá automaticamente identificar a falha e enviar o tráfego para o ent1. As partições cliente continuarão utilizando o VIOS1 e a interrupção no tráfego é de 3 segundos.
Em caso de falha no switch físico onde está conectada a interface ent0 do VIOS 1? O comportamento é o mesmo do cenário anterior.
Em caso de falha no VIOS 1 ou nas suas duas interfaces físicas? O VIOS 2, através do canal de controle, identifica a falha após não receber mais as mensagens de heartbeat e automaticamente assume a responsabilidade do tráfego de rede das partições cliente. Neste caso, a interrupção do tráfego é de até 15 segundos.
Moral da história: neste desenho não temos pontos únicos de falha, entretanto, observamos que todo o tráfego de rede ocorre apenas pelas interfaces do VIOS primário, subutilizando as interfaces do outro VIOS.
Vale mencionar que no SEA Failover existe a possibilidade de enviarmos tráfego para o segundo VIOS através de um recurso chamado de Load Sharing, contudo, este balanceamento é feito por VLAN, que na maioria dos cenários possui estatísticas de uso bem diferentes, tornando este balanceamento pouco eficiente.
Mas existe uma alternativa…
Múltiplos Virtual Switches
Para conseguirmos distribuir melhor o tráfego, podemos adotar a estratégia com dois Virtual Switches, conforme mostra o diagrama abaixo.
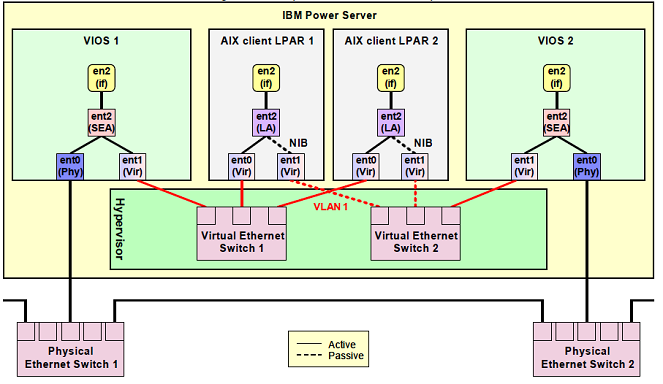
Neste cenário, cada VIOS está conectado através de sua interface virtual (ent1) a um Virtual Switch: VIOS 1 no Virtual Ethernet Switch 1 e VIOS 2 no Virtual Ethernet Switch 2. As partições cliente agora também possuem duas interfaces, cada uma conectada a um Virtual Switch.
O segredo desta estratégia está no Link Aggregation criado nas partições cliente – representado pelo ent2. O NIB, como citado anteriormente, é um Link Aggregation onde apenas uma das interfaces fica ativa e a outra interface fica inativa. A interface inativa assume o tráfego de rede apenas em caso de falha na outra interface.
Portanto, o balanceamento torna-se mais seletivo. Podemos configurar o Link Aggregation das partições alternando entre as interfaces ativa e inativa. Ou seja, a partição 1 usa a interface ent0 como ativa, que assim envia o tráfego para o VIOS 1, e a partição 2 usa a interface ent1, que envia o tráfego para o VIOS 2. Desta maneira o tráfego fica melhor distribuído.
Pelo fato de utilizar dois Virtual Switches, esta estratégia também suporta VLAN Tagging.
E qual é a desvantagem?
Complexidade. Pelo fato de exigir duas interfaces nas partições cliente e uma configuração de Link Aggregation adicional, tanto o provisionamento das partições como o gerenciamento das interfaces de rede virtuais exigem procedimentos adicionais quando comparados ao SEA Failover.
Conclusão
Para os cenários onde a distribuição de tráfego de rede é equalizada entre as diferentes VLAN, o SEA Failover com o Load Sharing é, sem dúvida, a melhor alternativa, pois mantém a complexidade longe das partições cliente.
Agora, quando há uma distribuição de tráfego muito desigual entre as VLANs, ou até mesmo a não existência de VLANs, a estratégia com múltiplos Virtual Switches agrada pelo fato de podermos balancear melhor a carga, justificando melhor o investimento nas interfaces de rede dos nossos servidores.
Referências
Miller, Glenn. Using Virtual Switches in PowerVM to Drive Maximum Value of 10 Gb Ethernet. IBM. Acessado em 14-04-2014.
Não conheço nada de power mas achei legal o artigo, bem didático.